
最近用到spark,把本地搭建spark on yarn 集群的步骤记录一下
| IP | 主机名 |
|---|---|
| 192.168.22.137 | spark-master |
| 192.168.22.150 | spark-slave1 |
更改主机名
确定每个节点的主机名与它在集群中所处的位置相同
如果不同,需要修改vi /etc/hostname
重启生效
可能需要些安装某些工具包
- 更换sources源
1
vi /etc/apt/sources.list
1 | deb http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse |
apt install net-tools
apt-get install iputils-ping
修改各主机的hosts文件
vi /etc/hosts
添加以下内容
1 | 192.168.22.137 spark-master |
SSH免密登录
我看了网上别人的说只需要安装server,但是我没有成功,我安装了server和client才行
1 | apt-get install openssh-client |
关于ssh服务可以参照这个链接
http://linux.it.net.cn/e/server/ssh/2015/0501/14838.html
紧接着就是配置各主机的免密登录
- 所有的主机都需要生成私钥和公钥(直接回车)
ssh-keygen -t rsa
- 将所有主机的
~/.ssh/id_rsa.pub都要放在master节点的~/.ssh/目录下(最好更改用以区分)
我使用的lrzsz工具(有点笨)。之后再主机执行
你也可以使用scp ~/.ssh/id_rsa.pub root@<hostname|ip>:~/.ssh/id_rsa.pub.slave1
- 将所有公钥加到用于认证的公钥文件authorized_keys中
1
cat ~/.ssh/id_rsa.pub* >> ~/.ssh/authorized_keys
此时~/.ssh/再将~/.ssh/authorized_keys拷贝其他节点,到此个主机就完成了免密登录
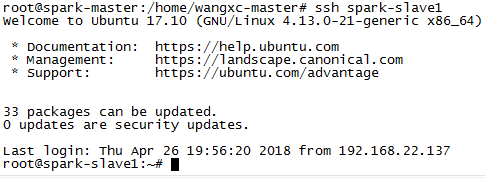
验证一下:
1 | ssh spark-master |
如果出现如下,就说明你成功了
所需环境配置
准备软件
用的版本不是最新的,看个人需要,但要保证各软件的版本要互相支持
1 | . |
可直接去各大官网下载,如果你想省事,直接从网盘里下载也行
https://pan.baidu.com/s/1vSu-6OTMvkROCBsiJwbMWQ
统一配置环境
我将所有的软件放在/spark/software/目录下、解压与修改文件名,然后统一配置环境变量
vi /etv/profile
假如如下内容
1 | export JAVA_HOME=/spark/software/java |
然后执行source /etc/profile 另其生效
然后测试,出现如下说明成功了
当然你也可以吧hadoop和spark假如path中,这样就可以随时使用hdfs和spark-submit命令了
其他主机做同样的操作
提示:各主机最好都统一路径,这样修改一个文件,然后将文件直接远程拷贝到其他主机上就行了
HADOOP配置
在/spark/software/hadoop/etc/hadoop目录下需要配置以下几个文件:
1 | hadoop-env.sh, |
hadoop-env.sh
export JAVA_HOME=/spark/software/java
yarn-env.sh
export JAVA_HOME=/spark/software/java
slaves
1 | spark-slave1 |
(这里我只添加了一个slave,你也可以把master加上去)
core-site.xml
添加如下:
1 | <property> |
hdfs-site.xml
添加如下:
1 | <property> |
maprd-site.xml
添加如下
1 | <property> |
yarn-site.xml
添加如下
1 | <property> |
以上配置完毕之后,要同步到其他主机上,因为配置了免密,可以这样操作
1 | scp /spark/software/hadoop/etc/hadoop/ root@spark-slave1:/spark/software/hadoop/etc/hadoop/ |
HADOOP启动
进入/spark/software/hadoop目录下
- 格式化namenode
bin/hfds namenode -format
当出现“successful”的字样,就说明成功了
启动dfs
sbin/start-dfs.sh启动yarn
sbin/start-yarn.sh
接下来验证,spark-master 执行jps,有以下几个进程
1 | 27570 SecondaryNameNode |
每个slave上应该有以下几个进程
1 | 18324 DataNode |
可以在任意一台主机上的浏览器输入
1 | http://spark-master:8088/cluster/nodes yarn管理界面 |
spark 环境
在/spark/software/spark/conf目录下修改spark-env.sh(需先拷贝spark-env.sh.template)文件
1 | export SCALA_HOME=spark/software/scala |
同样在slaves文件中添加子节点
1 | spark-slave1 |
同样将这两个文件发送到其他主机对应位置
然后在/spark/software/spark目录下执行
1 |
集群配置参考
- http://wuchong.me/blog/2015/04/04/spark-on-yarn-cluster-deploy/
https://www.jianshu.com/p/aa6f3a366727

