
在工作中,我开始接触并使用ES的笔记
以下基于Elastic 5.4版本
部署
这里使用Docker部署
- 获取镜像
docker pull elasticsearch:5.4 - 启动
docker run -d -p 9200:9200 -p 9100:9100 elasticsearch:5.4
注意: 通过docker ps可以看到es的启动情况,如果没有成功可以通过docker logs elasticsearch:5.4 查看日志,一般会报这个错误Cannot allocate memory,此时加上-e ES_JAVA_OPTS="-Xms512m -Xmx512m",全命令即
1 | docker run -d -p 9200:9200 -p 9100:9100 -e ES_JAVA_OPTS="-Xms512m -Xmx512m" elasticsearch:5.4 |
ES 的相关使用
查看状态
GET _cat/health?v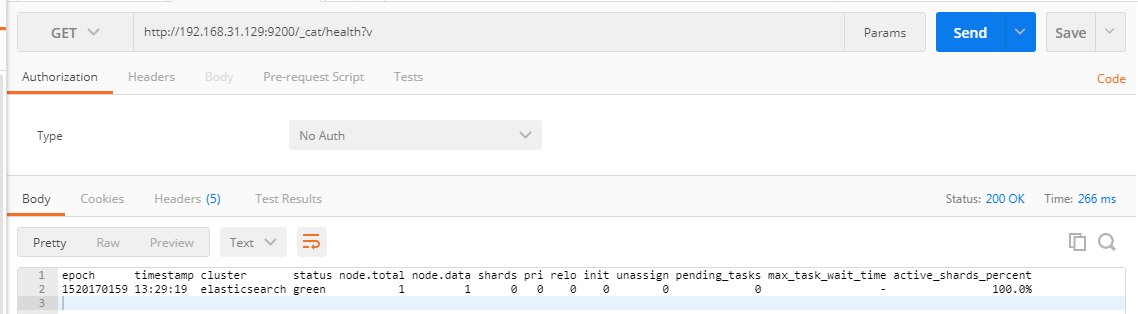
查看节点列表
GET _cat/nodes?v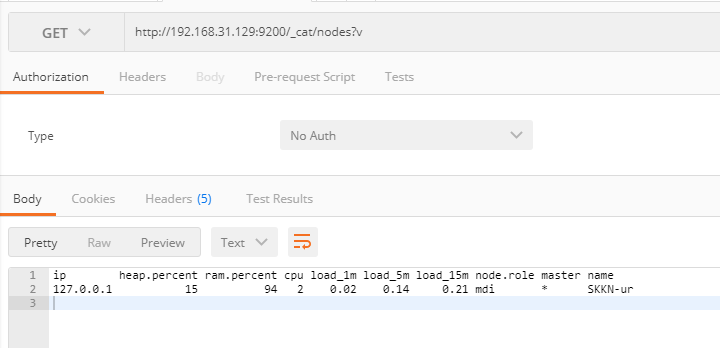
创建索引
PUT index?pretty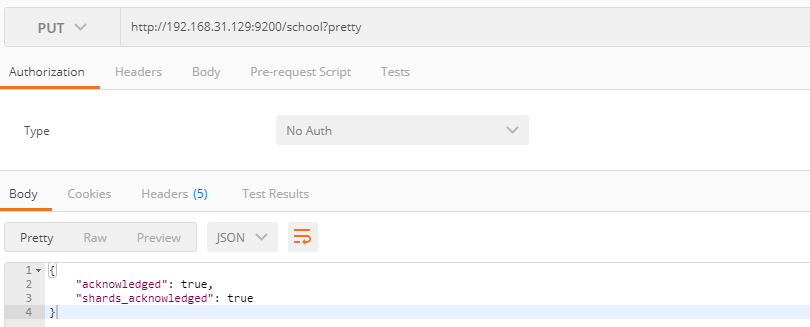
查看索引列表
GET _cat/indices?v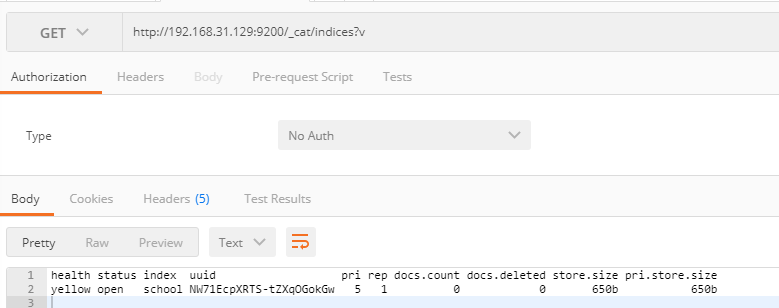
删除索引
DELETE index?pretty
创建Mapping
POST index/type/_mapping
1 | { |
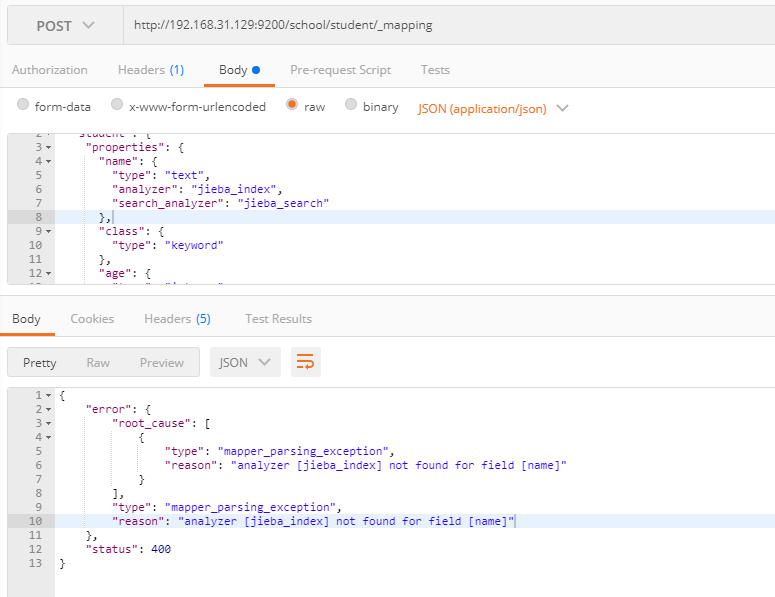
因为没有安装结巴分词插件,所以创建失败
查看Mapping
GET index/_mapping?pretty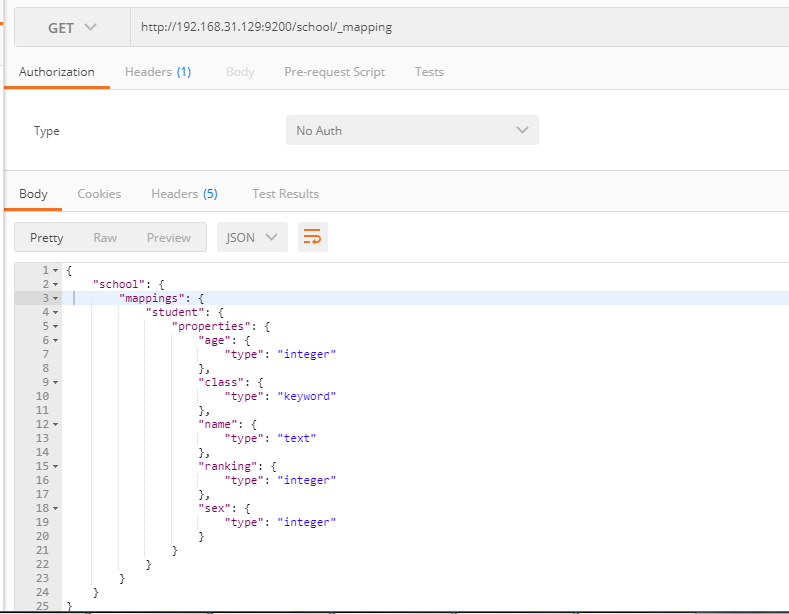
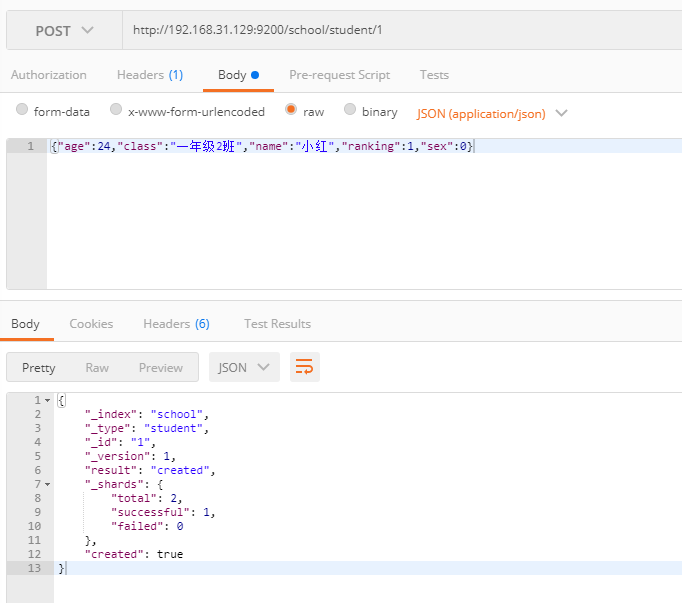
索引文档
POST index/type/{id}
1 | {"age":23,"class":"一年级2班","name":"小黑","ranking":13,"sex":1} |
删除所有文档数据
POST index/type/_delete_by_query?conflicts=proceed
1 | { |
重点
ES支持的类型
这里用的是5.4
| 类型 | 包括 |
|---|---|
| String | text, keyword |
| Number | long, integer, short, byte, double, float, half_float, scaled_float |
| Date | date |
| Boolean | boolean |
| Binary | binary |
| Rande | integer_range, float_range, long_range, double_range, date_range |
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/5.4/mapping-types.html
关于String类型的text和keyword,我的理解是
如果该字段需要被分词,就使用text,如果不需要分词就使用keyword
分词
分词在ES中是比较重要的,因为分词的好坏直接影响到搜索结果准确度的高低!
分词器 接受一个字符串作为输入,将 这个字符串拆分成独立的词或 语汇单元(token) (可能会丢弃一些标点符号等字符),然后输出一个 语汇单元流(token stream) 。
https://www.elastic.co/guide/cn/elasticsearch/guide/current/standard-tokenizer.html
分词分为两种:索引分词、搜索分词
在创建mapping的时候声明,如上
1 | "name": { |
(下面是个人观点,如有问题,欢迎指出)
举个例子:
“我爱吃肠粉” 经过分词后可能有以下几个结果
- 我,爱,吃,肠,粉
- 我爱,吃,肠粉
- 我爱吃,肠粉
- 。。。
那么分词在ES中是怎样应用的?
当“我爱吃肠粉”索引到ES中之后,ES中对此句的描述变为“我”,“爱”,“吃”,“肠”,“粉”,此为索引分词
当用户查询“我”的时候,ES会将分词结果中包含“我”的结果输出,所以“我爱吃肠粉”会被搜索出来;如果输入“我爱”,而且搜索分词的结果也为“我爱”的时候,“我爱吃肠粉”则不会被搜索出来
ES默认的分词为“英文分词”,即“我爱吃肠粉”的第一种分词结果,这很显然不符合我们一般的应用场景,所以这个时候就需要引入第三方插件了,如“结巴分词”和IK分词
IK: https://github.com/medcl/elasticsearch-analysis-ik
Jieba: https://github.com/sing1ee/elasticsearch-jieba-plugin
按照自己的具体搜索场景来选择合适的分词插件
term 和 match 的使用
可学习这篇博客:http://www.cnblogs.com/yjf512/p/4897294.html 写的详细全面
2018年3月5日 更新
更新
PUT /index/type/id
1 | { |
这个id是es自己的id(可在索引的时候设置id)
java实现
1 | UpdateRequest updateRequest = new UpdateRequest(); |
https://www.elastic.co/guide/cn/elasticsearch/guide/current/update-doc.html
updateByquery
POST index/_update_by_query
1 | { |
ctx._source 为 一条记录对象
上面是“将查出来的文档中likes的值加1”
java实现
1 | TransportClient client = elasticSearchClient.getClient(); |
https://www.elastic.co/guide/en/elasticsearch/reference/5.4/docs-update-by-query.html
以上就是我在工作中使用ES 总结的内容,入门到会使用应该是没问题。之后会继续学习并更新~
CSDN:http://blog.csdn.net/qqhjqs?viewmode=list
博客:http://vector4wang.tk/
简书:https://www.jianshu.com/u/223a1314e818
Github:https://github.com/vector4wang
Gitee:https://gitee.com/backwxc

