
最近工作上需要一些企业的详细的数据,工商信息啦,基本信息啦,还有一些关系图(投资关系、人物图谱)之类的,然后我来负责从企查查上弄些数据。
强调:下面只是快速实现数据抓取的思路,没有详细的代码,同时也拒绝伸手党。
现实中,一些工商信息网站会被无数的爬虫“骚扰”,所以网站的反爬虫策略也是越来越高,就拿企查查来说,基本的信息是直接可访问的,但是像人物图谱和企业图谱这些内容还是需要登录的,
特别是人物图谱,非VIP会员,一天也只能看两次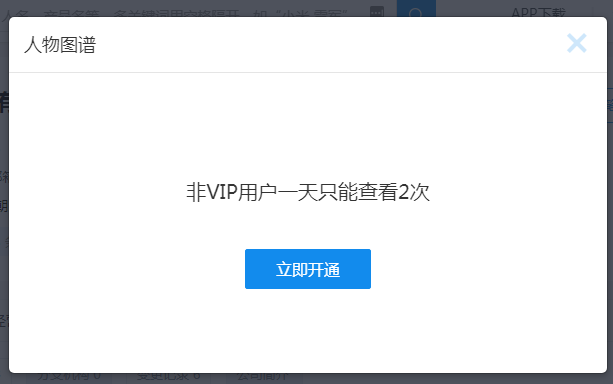
企查查的登录也是做了很多限制
比如图片验证码啊,数字验证码啊,还有验证码异常出现刷新按钮啊等等(之前在做的过程中发现的没有及时截图)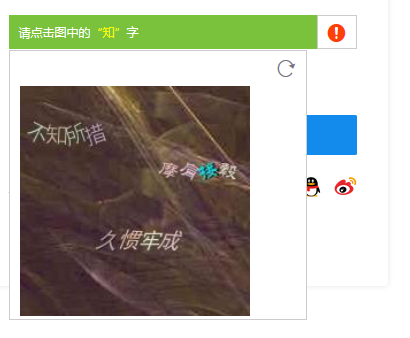
但是有了selenium这些都不是问题~接下来按照如下思维导图做一个抓取的分析(代码想了许久还是不贴出来了)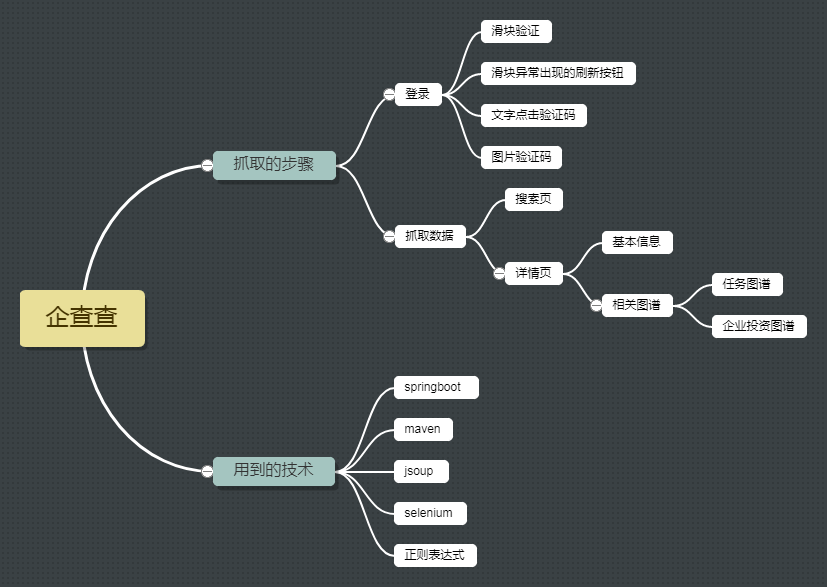
登录
滑块验证
首先出场的是滑块验证,这个可以使用Selenium中的Actions.clickAndHold()来破防,打开浏览器Element面板,边滑动滑块边观察Html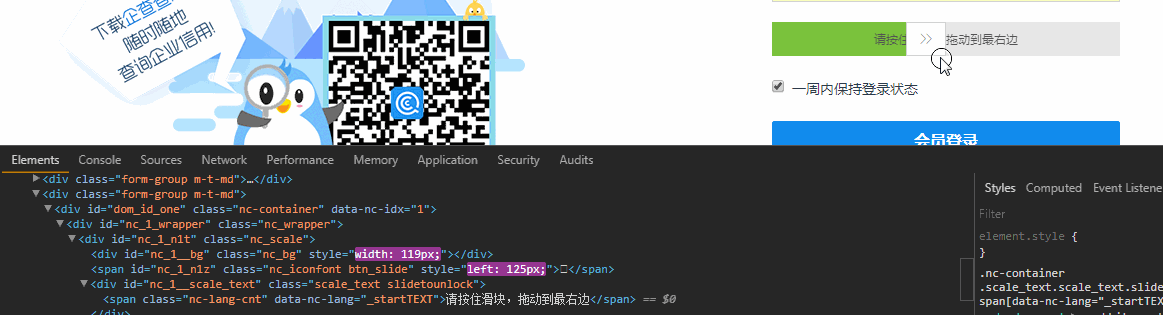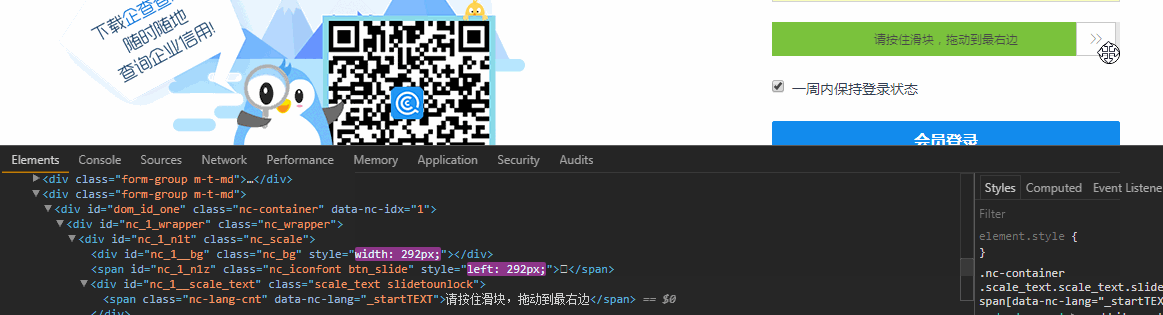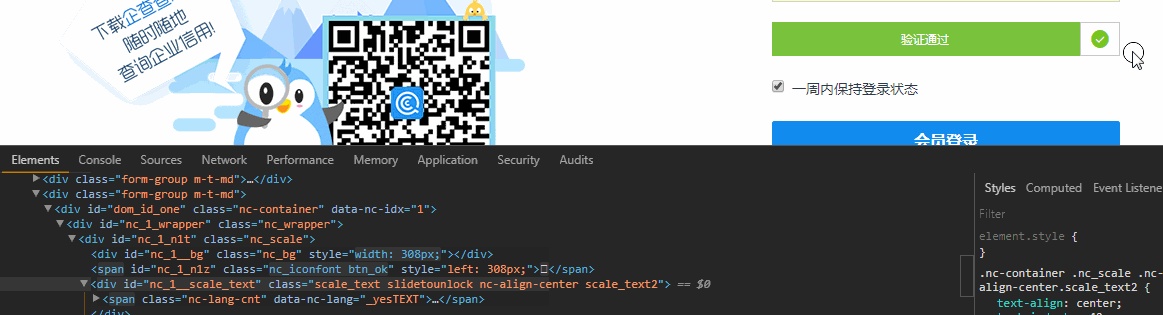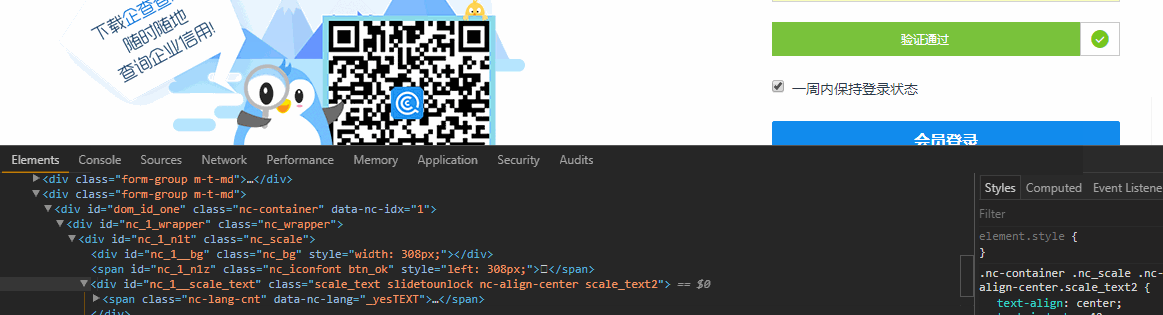 这说明滑块不只是单纯的移动到右侧,还导致其他样式改变,这也说明你不能直接通过修改Html的方式改变滑块的位置来验证 ,Ps:有的网站只要滑块在最终的位置,就认为验证通过了。
这说明滑块不只是单纯的移动到右侧,还导致其他样式改变,这也说明你不能直接通过修改Html的方式改变滑块的位置来验证 ,Ps:有的网站只要滑块在最终的位置,就认为验证通过了。
使用java和selenium模拟滑动滑块
1 | WebElement dragger = driver.findElement(By.cssSelector("#nc_1_n1z")); |
target 和 offset 的值自己去口算一下~
图片型验证码
不知为何,我每次用代码模拟滑块的时候页面都会弹出图片型验证码,而人工滑动却不要,这让我很费解。
一般像图片型验证码和数字型验证码有的人可能会自己去研究算法来解决,什么机器学习啦,深度学习啦等等。这里不要这么高深的,统统用打码平台,用法和价格自行百度,可以这样理解:你通过Http的方式提交图片和要求,平台会返回给你相应的结果。如数字啦、文字的坐标啦、多个文字的坐标等等。
仔细分析下面的截图所对应的的Element
我们可以看出验证要求在青色横条中,而目标文字在下面的方块中,这是两个不同的Element,而打码平台的要求是给他一张完整的图片,这个当时我想都没想,立即决定使用selenium截图的方式将横条和方块分别保存下来,然后通过代码将其拼接为一张图片,最后将一整张图提交给打码平台。如下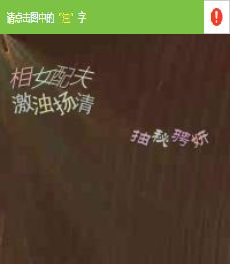
然后平台会返回给你一个坐标如(x,y),刚刚提到了方块图他是单独的一个Element,所以目标y还要减去横条的高度即(x,y-34),这个时候你以为搞定了?NoNoNo!通过浏览器的定位元素,可以看到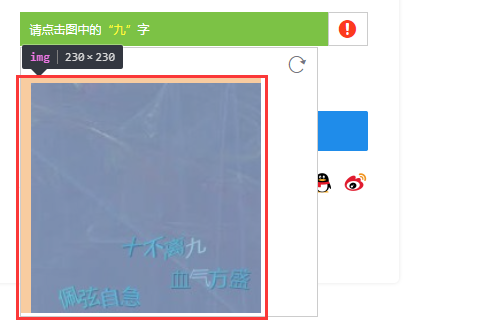
方块所在的Elemnt 有个样式margin-left,所以我们还要减去这个值,即最终的最标为(x + 2, y - 34)为什么是2而不是10,这个是因为我尝试了很多次,发现2才可以。。。
好了接下来就是根据坐标去点击,要用到这个方法:
1 | Actions action = new Actions(driver); |
这里注意下,moveToElement是以element的左上角为原点,往右是X,往下是Y
数字验证码
(没有截图,只有代码截的图)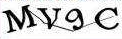
这样的就很普通了,我们依然交给打码平台,通过使用返回的“MV9C”来通过此验证。
异常刷新
(这个也没有截图)出现这种情况我猜测是企查查检测到你这边频繁的登录或验证,形式就是滑动条上出现了“刷新”超链接,这个只要定为到“刷新”Element,点击一下就ok,如下
1 | WebElement err = reloadElement.findElement(By.cssSelector("#dom_id_one > div > span > a")); |
注意:登录的过程中每一个验证都可能有失败的情况,所以每个处理最好加上一个循环,直到验证通过再跳出循环进入下一步操作
抓取数据
这里重点讲企业详情页
对于企查查来说只要登录这块搞定了,其他数据不是问题,就是简单的分析下每个数据的请求地址,然后用selenium模拟请求就行了。
人物图谱

1 | URL:http://www.qichacha.com/company_opercorview?name=马化腾&personId=p03cf330a686332cfe9cb8f36a8f3ab8&keyno=f1c5372005e04ba99175d5fd3db7b8fc |
投资图谱
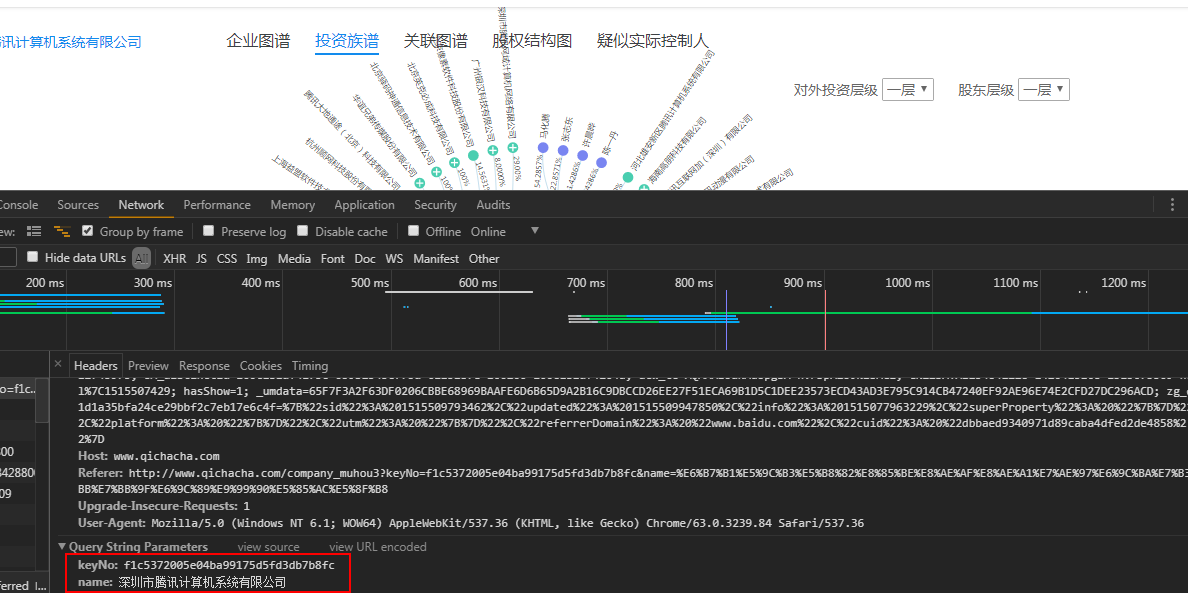
1 | URL:http://www.qichacha.com/company_relation?keyNo=f1c5372005e04ba99175d5fd3db7b8fc&name=深圳市腾讯计算机系统有限公司 |
很直观的就能看到请求地址,然后将返回的JSON字符串处理一下,就得到了你想要的数据
这里不做太多的赘述。
贴个控制台的图
总结
总的来讲企查查的网站相对于天眼查还是比较容易突破的,只要把登录这块完美处理好,其他就是解析上的问题了。
话说企查查并没有对访问IP做限制处理,只是如果用一个账号访问次数太多之后,中间也会出现滑块认证,但是不要担心,你可以把登录那块的验证逻辑直接搬过来即可,你敢信?
爬虫不是我的主要工作,我只是对数据抓取这块比较感兴趣,还有在工作中有些数据需要抓取,所以我也就担当了半个爬虫的角色,最近自己在使用jsoup写一个简易爬虫框架(参照webmagic),有兴趣得可持续关注我,如果有必要的话,我会写一些爬虫教程,让小白变大白(●—●)绰绰有余
CSDN:http://blog.csdn.net/qqhjqs?viewmode=list
博客:http://vector4wang.tk/
简书:https://www.jianshu.com/u/223a1314e818
Github:https://github.com/vector4wang

